🚩知识背景预设
SQL语句中的左外查询和右外查询(左上图和右上图)是很常见的操作,故在此不多赘述,但基于左外查询和右外查询衍生出来的两种变式并不易于理解,如下图的左中和右中所示:
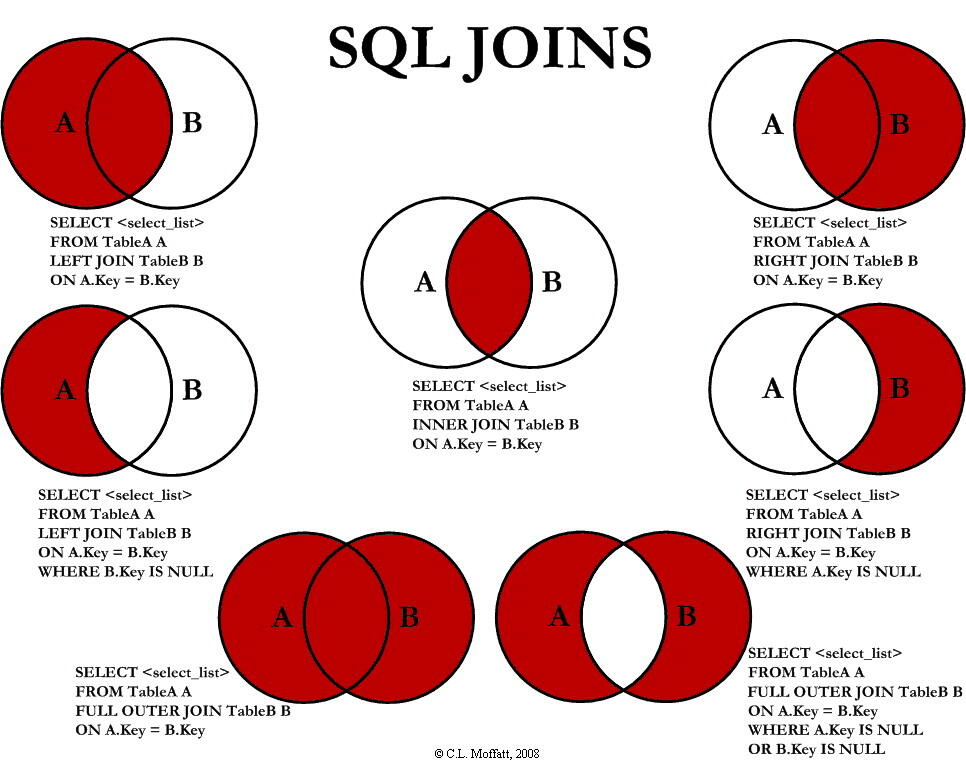
以左中图为例,这是基于左外连接变化而来的情况,想要得到它可以分为如下步骤:
- 使用左外连接,以A为主表,B为从表
- 使用
WHERE子句过滤掉A表与B表的内连接(即A与B的交集)
又有如下公式通解可用:
SELECT 字段列表
FROM A表
LEFT JOIN B表 ON 关联条件
WHERE 从表关联字段 IS NULL;我们要探讨的问题便是公式通解中的WHERE子句为何判断的是从表的关联字段,而非其他
🎯实际问题引入
在了解完知识背景后,我们通过一个实际案例来引入问题
0️⃣数据源
我们有两张表,一张表为 employees表,另一张表为 departments表
- employees表:存放员工的员工ID、姓名和部门ID等信息
- departments表:存放部门的部门ID和部门名称等信息
我们首先来查看 employees表的表结构:
+----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+-------------+------+-----+---------+-------+
| employee_id | int(6) | NO | PRI | 0 | |
| first_name | varchar(20) | YES | | NULL | |
| last_name | varchar(25) | NO | | NULL | |
| email | varchar(25) | NO | UNI | NULL | |
| phone_number | varchar(20) | YES | | NULL | |
| hire_date | date | NO | | NULL | |
| job_id | varchar(10) | NO | MUL | NULL | |
| salary | double(8,2) | YES | | NULL | |
| commission_pct | double(2,2) | YES | | NULL | |
| manager_id | int(6) | YES | MUL | NULL | |
| department_id | int(4) | YES | MUL | NULL | |
+----------------+-------------+------+-----+---------+-------+由 employees表结构可知,每一位员工都有其对应的 employee_id(员工ID)和 department_id(部门ID)及其他数据
然而,employees表中有一位特殊的员工,他由于刚入职还没有部门,他的员工ID是178,我们暂且叫他菜鸟
SELECT employee_id,department_id FROM employees WHERE department_id IS NULL;
/*+-------------+---------------+
| employee_id | department_id |
+-------------+---------------+
| 178 | NULL |
+-------------+---------------+*/再来观察 departments表,还是老样子先来看看它的表结构:
+-----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+-------------+------+-----+---------+-------+
| department_id | int(4) | NO | PRI | 0 | |
| department_name | varchar(30) | NO | | NULL | |
| manager_id | int(6) | YES | MUL | NULL | |
| location_id | int(4) | YES | MUL | NULL | |
+-----------------+-------------+------+-----+---------+-------+仔细观察 employees表和 departments表,不难发现:我们可以通过 department_id这个字段来将两张表建立起连接来查询出每位员工的 department_name(部门名称),有如下语句:
SELECT emp.employee_id,emp.department_id,dept.department_name
FROM employees emp INNER JOIN departments dept
ON emp.department_id = dept.department_id;
/*+-------------+---------------+------------------+
| employee_id | department_id | department_name |
+-------------+---------------+------------------+
| 200 | 10 | Administration |
| 201 | 20 | Marketing |
| 202 | 20 | Marketing |
| 114 | 30 | Purchasing |
| 115 | 30 | Purchasing |
...还有更多就不复制了*/这是一个标准的内连接,通过内连接我们很轻松地将几乎每位员工的部门名称都查询了出来
然而,由于菜鸟没有部门ID,也就不满足连接条件,这次查询的结果集中并没有他的记录
1️⃣需求升级
有一天,BOSS需要查看所有员工的部门名称,并且即使某些员工没有部门(说的就是菜鸟)也要显示在结果集里
这时我们就需要拿出左外连接来实现BOSS的需求:
SELECT emp.employee_id,emp.department_id,dept.department_name
FROM employees emp LEFT JOIN departments dept
ON emp.department_id = dept.department_id;
/*+-------------+---------------+------------------+
| employee_id | department_id | department_name |
+-------------+---------------+------------------+
| 178 | NULL | NULL |
| 200 | 10 | Administration |
| 201 | 20 | Marketing |
| 202 | 20 | Marketing |
...还有更多就不复制了*/可以看到使用左外连接成功搞定了BOSS的需求,这就是左外连接的应用
2️⃣需求再升级
说了对内连接和左外连接不再赘述,还是说了那么多,究其原因是为接下来做铺垫,进入文章的核心
又有一天,BOSS心血来潮,说他就想要看看到底是谁还没有部门名称,这就进入我们的主题了
我们在数据源那部分得知,由于菜鸟刚刚入职,他还没有被分到具体的部门,因此他的 department_id字段为 NULL
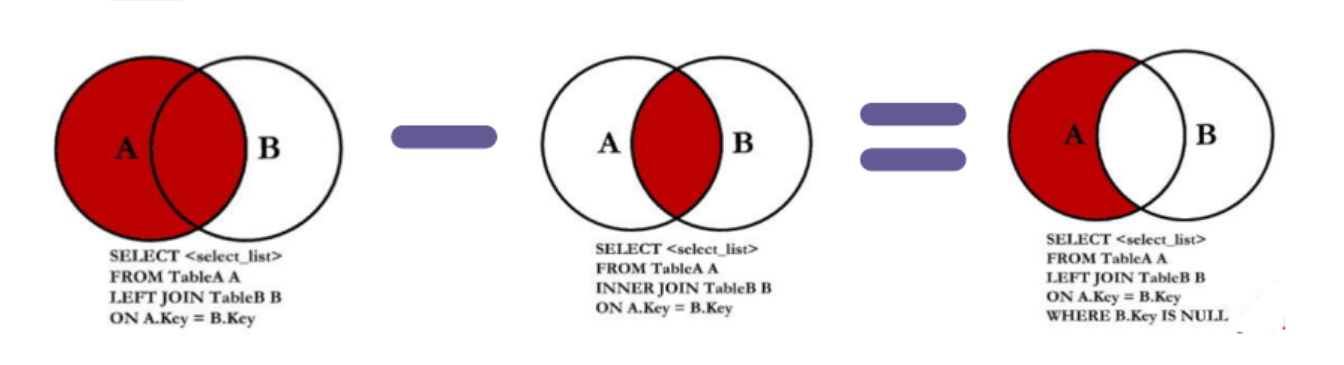
这就好办了,我们只需要再加一个 WHERE子句,把刚才左外查询结果集中的 department_id字段为 NULL的筛选出来就好,由此可得以下语句:
SELECT emp.employee_id,emp.department_id,dept.department_name
FROM employees emp LEFT JOIN departments dept
ON emp.department_id = dept.department_id
WHERE emp.department_id IS NULL;
/*+-------------+---------------+-----------------+
| employee_id | department_id | department_name |
+-------------+---------------+-----------------+
| 178 | NULL | NULL |
+-------------+---------------+-----------------+*/然而,这与我们开头知识背景中提到的公式通解相悖,在公式中的WHERE子句是这样的:WHERE 从表关联字段 IS NULL
我们使用的 WHERE emp.department_id IS NULL明明是主表中的关联字段,为何也跑出了相同的结果呢?是否是公式有误呢?
🔍问题深入剖析
1️⃣问题所在
在刚才的例子中,虽然使用的是 WHERE emp.department_id IS NULL也跑出了看似正确的结果集,但这样是歪打正着,错误的!
department_id为NULL的刚入职的新员工(比如菜鸟就是这种类型的)employees表中这位员工的department_id有数据,但在departments表中却没有对应的department_id与之相等,也就是该员工有部门ID,但该部门ID下却没有部门
对于第二种情况,举一个例子。有一位员工暂且叫他倒霉蛋。他的部门ID是999,但由于部门调整,他的部门已经不存在了但他还没有被分配到新的部门。此时他在 employees表中的 department_id仍是999,但在 departments表中却没有与999对应的部门名称了
+-------------+---------------+
| employee_id | department_id |
+-------------+---------------+
| 400 | 999 |
+-------------+---------------+因此,面对第二种情况,WHERE emp.department_id IS NULL就没办法把倒霉蛋也查询出来了,我们就需要使用正确的公式进行查询:
SELECT emp.employee_id,emp.department_id,dept.department_name
FROM employees emp LEFT JOIN departments dept
ON emp.department_id = dept.department_id
WHERE dept.department_id IS NULL;
/*+-------------+---------------+-----------------+
| employee_id | department_id | department_name |
+-------------+---------------+-----------------+
| 178 | NULL | NULL |
| 200 | 999 | NULL |
+-------------+---------------+-----------------+*/2️⃣公式原理逻辑分析
可以看到,我们自作聪明写的 WHERE emp.department_id IS NULL并没有办法覆盖到全部情况,那公式让我们通过筛选从表关联字段是否为NULL来达到要求,又是怎么实现的呢?
这就要从左外连接的特性说起,它除了把符合连接条件的行加入到结果集中,还把左表也就是主表中不符合连接条件的记录加入了进去
然而,左表中不符合连接条件的记录进是进去了,但是右表中也不知道找什么与它对应呀,毕竟不符合连接条件,于是就用 NULL填充
由如下语句我们可以直观感受出左外连接的特性:
SELECT emp.employee_id,emp.department_id,dept.department_name,dept.location_id,dept.manager_id
FROM employees emp LEFT JOIN departments dept
ON emp.department_id = dept.department_id
WHERE dept.department_id IS NULL;
/*+-------------+---------------+------------------+-------------+------------+
| employee_id | department_id | department_name | location_id | manager_id |
+-------------+---------------+------------------+-------------+------------+
| 178 | NULL | NULL | NULL | NULL |
| 400 | 999 | NULL | NULL | NULL |
+-------------+---------------+------------------+-------------+------------+可以看到,菜鸟那一行中凡是来自 departments表(从表)中的字段,全部都被设为了 NULL,倒霉蛋也是如此
WHERE从句中筛选 从表关联字段是否为 NULL
🚀公式进阶与变体
我们由刚才的公式原理逻辑分析得知,在左外连接下凡是不满足连接条件的记录中来自从表中的字段全部都设为了NULL,我们可不可以对公式进行改写?
我个人的见解:可以,但是最好不要
-- 此为改写后的公式,将从表关联字段改为了从表中的任意字段
SELECT 字段列表
FROM A表
LEFT JOIN B表 ON 关联条件
WHERE 从表中任意字段 IS NULL;我们现在运用改写后的公式再跑一下刚才的需求,得知:
SELECT emp.employee_id,emp.department_id,dept.department_name
FROM employees emp LEFT JOIN departments dept
ON emp.department_id = dept.department_id
WHERE dept.location_id IS NULL;
/*+-------------+---------------+-----------------+
| employee_id | department_id | department_name |
+-------------+---------------+-----------------+
| 178 | NULL | NULL |
| 200 | 999 | NULL |
+-------------+---------------+-----------------+*/从结果集来看,改写后的公式也可以应对需求,也完全正确可以实际应用,但我个人还是不建议这么做,有如下原因:
- 使用从表关联字段更加保险:我们在连接两张表中使用的就是从表关联字段,证明从表中一定存在从表关联字段且一定可用
- 从表中的其他字段可能不存在:其他字段可能在从表里并不存在,而从表关联字段是一定存在的,如果连从表关联字段都不存在了,那早就连接不起来了
- 更加易读:使用从表中的其他字段可能出现"魔法值"的情况,让其他读你写的SQL语句的人很懵逼,不知道你到底要干什么

